I need data from a website, and they don’t provide an API to consume the data. What can I do here? And how complicated or challenging will it be to do?
There are multiple options when you need to scrape data from a website. Which one you choose is highly dependent on your use case. Just understand that you have various issues to solve. I would not recommend it for one-off tasks as, in most cases, you will be faster doing it by hand. Perhaps you could use Excel to Import data from the web in such a scenario?
You can scrape the data from the website. But depending on the website, you will have different issues:
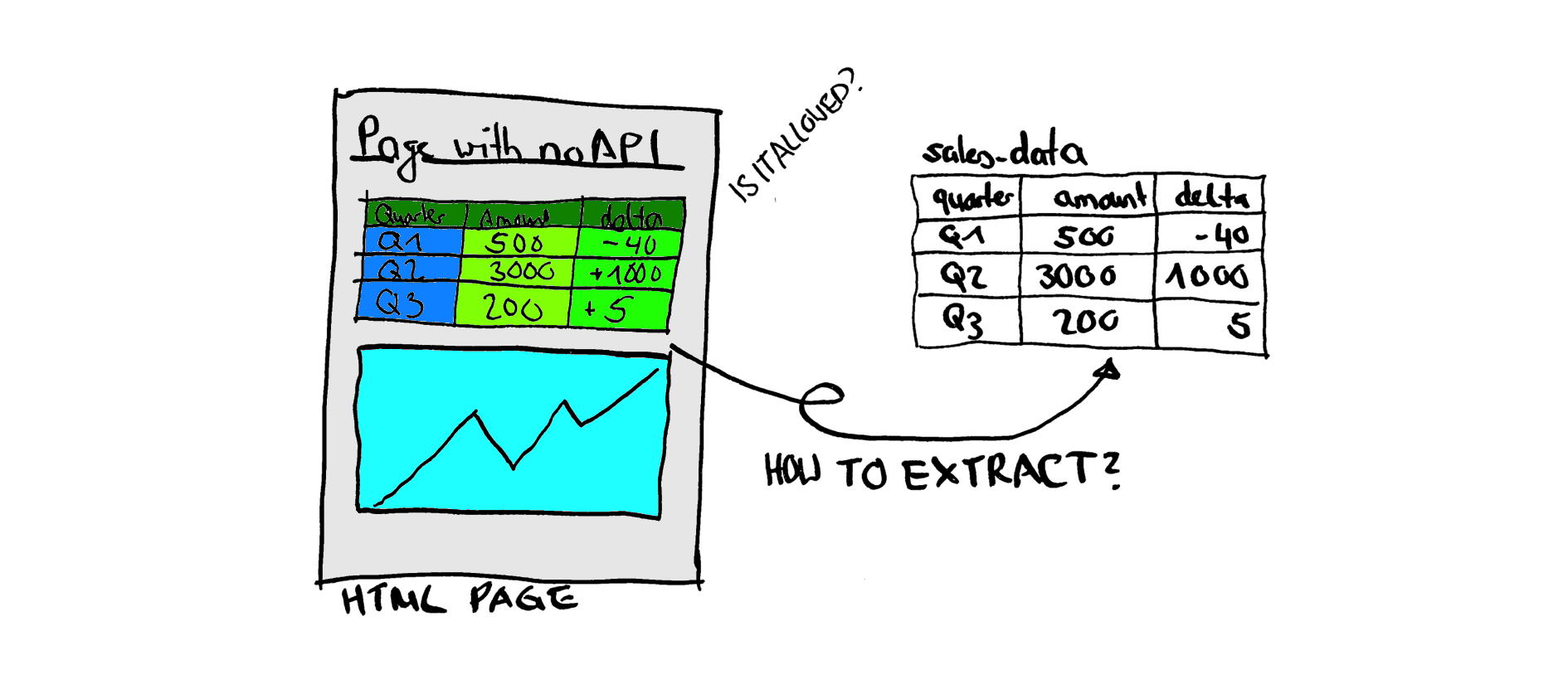
When scraping data from a website, you need to solve multiple issues. The first question is, how do you extract the data? And then, you also need to consider the legality and moral aspect of your actions.
How to scrape?
The most straightforward setup to extract data from a web page is to request the website via an HTTP request. And then extract the data either by using an HTML parser like (Beautiful Soup (Python) or Nokogiri for Ruby), sometimes you can also get away with just using regex and matching your data manually. But be aware that I would only use this way for the simplest scenarios and one-off projects as it is tough to maintain and keep running.
Here is a short example of how you can extract data from a page with ruby and regex. We do not match the whole result in a single regex (it could be done this way), making the regex a lot more complex. So we use the first regex to find the beginning of each article link tag. And next, we iterate over these results and do a secondary match starting from the end location of the opening article link tag, which yields a nice list of the blog post titles.
#!/usr/bin/env ruby
require 'open-uri'
require 'net/HTTP
response = Net::HTTP.get_response(URI.parse('https://www.vlearns.xyz')
html = response.body
# Regex to match the beginning of each article list. It looks like this:
# <a href="/example-post/" class="article-link"
res = HTML.to_enum(:scan, /<a href="\/.*?\/" class="article-link"/).map { Regexp.last_match }
res.each do |r|
reduced_html = html[r.end(0)..-1] # A substring from the full HTML starting at the end of our link match
# We search from the start of the matched link and search for the title of the link
puts reduced_html.match(/<h2 class="article-title">(.*?)<\/h2>/m)[1].strip()
end
And now the same example using but using nokogiri:
#! /usr/bin/env ruby
require 'nokogiri'
require 'open-uri'
# Fetch and parse HTML document
doc = Nokogiri::HTML(URI.open('https://www.vlearns.xyz'))
# Find all article titles via CSS
doc.CSS('a > div > div.article-data > h2').each do |link|
puts link.content.strip()
end
We now have an external dependency, but on the other hand, the code is a lot shorter. In this example, we traverse to the correct element using the CSS method and provide it with the CSS selector path to the element we want to extract.
Homepages with countermeasures
Some homepages don’t load correctly when no JavaScript is executed. Amazon.com is an example of such a site 1. Most of the simple scraping methods don’t provide JavaScript execution. So you can’t directly extract the data from such pages. The solution I’ve used in this situation is to load the page in a regular browser and inject additional JavaScript into the document, which does the extraction for me. This does not work in every browser. I was lucky that I was working on an iOS app and could use the web view component, which allows injecting arbitrary js into a webpage. Another option is to use a browser automation tool like puppeteer, which will enable you to automate chrome.
Scarping SPA pages
When you need to extract data from a SPA (Single Page Application), I would not use scraping at all and instead try to use the underlying API the page uses to request its data. Open up the Web Inspector window in your browser, switch to the network tab, and load the page. Now you should see the request the SPA is making to its hidden API. And you can start implementing the same calls to access the data you want.
Further important points to look out for
Legality
In most cases, you are not allowed to scrape the data as it does not belong to you. Depending on your use case, you are in a grey area. If you scrape your data like, for example, your viewing history on Netflix, I see fewer issues than when you scrape data from, let’s say, IMDb. I would not use scraping when I want to use the data for a public or commercial project. I think you need to find a different source in such a case. Or you could try to get a license for the data and look with them to get it in a better format.
Authentication
When the website is not public, you need to log in with an account (especially if it needs a second factor which means you can’t do it in the background). Another point here is that when you have an account and the website owners know you, they could theoretically close your account when they discover that you misuse it. Especially important when you try to scape your banking accounts.
Cat and mouse
You will constantly need to adjust your code to the changes on the page. As updates change the HTML structure, you need to find your data. Speaking from my own experience here, it is not fun to fix your scraper ever-time you want to use it :-(. And some pages also have active countermeasures against scraping.
Speed
As the scraping process is complicated and error-prone, I would always set up such a system as a background job. And never directly start scraping data as a result of a page hit. The background job should scrape the pages regularly and save the data in a database, from where you can use the data then—setting it up in such a way prevents you from running into rate limits and makes your app speed independent from the speed of the scraped page.
Summary
Extracting data from homepages is a big topic. And I’ve only scratched the surface with this post. But I hope that you got an overview of what is possible to do. And how you can proceed from here. Thank you for reading it. I would appreciate it if you signed up for my email list never to miss another post.
-
When I start reading a book, I use this to automate posting book details to my blog. I copy the amazon page to my blogging app, and it automatically extracts the book’s details (title, author, page counts). ↩︎